We all hoard things. A link a friend sends, a screenshot of a paragraph that hit different, a PDF we swear we'll read, a half-formed note typed at 2am. The capturing is easy. The finding it again is where everything falls apart — buried in browser bookmarks, lost in some note app, gone the moment we forget the exact words we used.
Recall was my attempt to fix that without selling my data to do it. The pitch is simple: paste a URL, drop a file, or jot a note — and never organise a single thing — yet still find any of it later by describing what you half-remember. The hard part was making that work while keeping everything you own actually yours.
Here's what building it taught me:
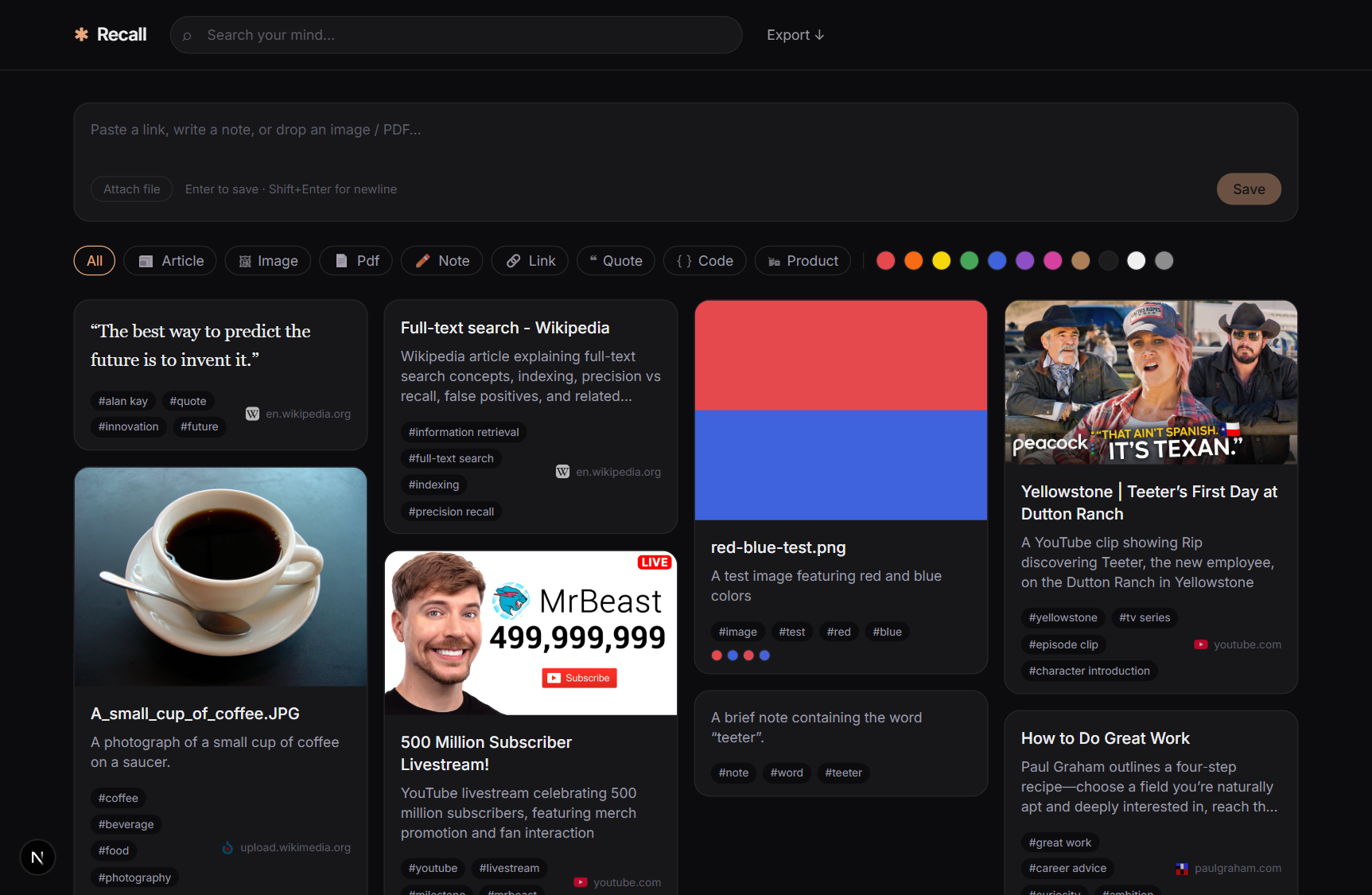
- Zero-friction capture is a systems problem, not a UI one. Every way an item enters Recall — a pasted URL, an uploaded image or PDF, a quick note, or the browser extension — converges on the same
cardstable. URLs get fetched server-side and run through Mozilla's Readability (the engine behind Firefox Reader Mode) to strip the ads and pull out clean article text; PDFs get their text extracted so they're searchable; images get their dominant colors pulled out withsharpin about 10ms. One atomic unit, the Card, no matter where it came from. - The AI should work for you in the background, then get out of the way. Creating a card responds to you immediately. Only after the response is flushed does the enrichment run — auto-tagging, a one-line summary, and a semantic embedding — via Next.js's
after()hook. No queues, no workers, no spinners. And crucially, enrichment never throws: a card stays fully usable even if every AI step fails. - Search should work whether you remember the words or only the idea. This was the fun one. Recall runs full-text search and vector similarity search in a single SQL query, then fuses the two rankings with Reciprocal Rank Fusion. A card that either method ranks highly surfaces; a card both agree on wins. So "pgvector HNSW" finds it, and so does "that article about fast similarity search in Postgres."
- Privacy isn't a feature you bolt on — it's an architecture. The embeddings that power semantic search are generated locally, in-process, with
nomic-embed-textrunning through transformers.js. They never leave the machine. The only external call is optional tagging, and settingDISABLE_EXTERNAL_AI=trueshuts even that off — at which point Recall makes zero external AI calls and still searches by meaning. No analytics, no telemetry, no third-party scripts. - Owning your data has to be more than a promise. One click exports the entire library as a zip — structured JSON, a Markdown file per card with YAML frontmatter (drop it straight into Obsidian), and every original file. Built with streaming so memory stays flat no matter how big the library gets. Nothing held hostage.
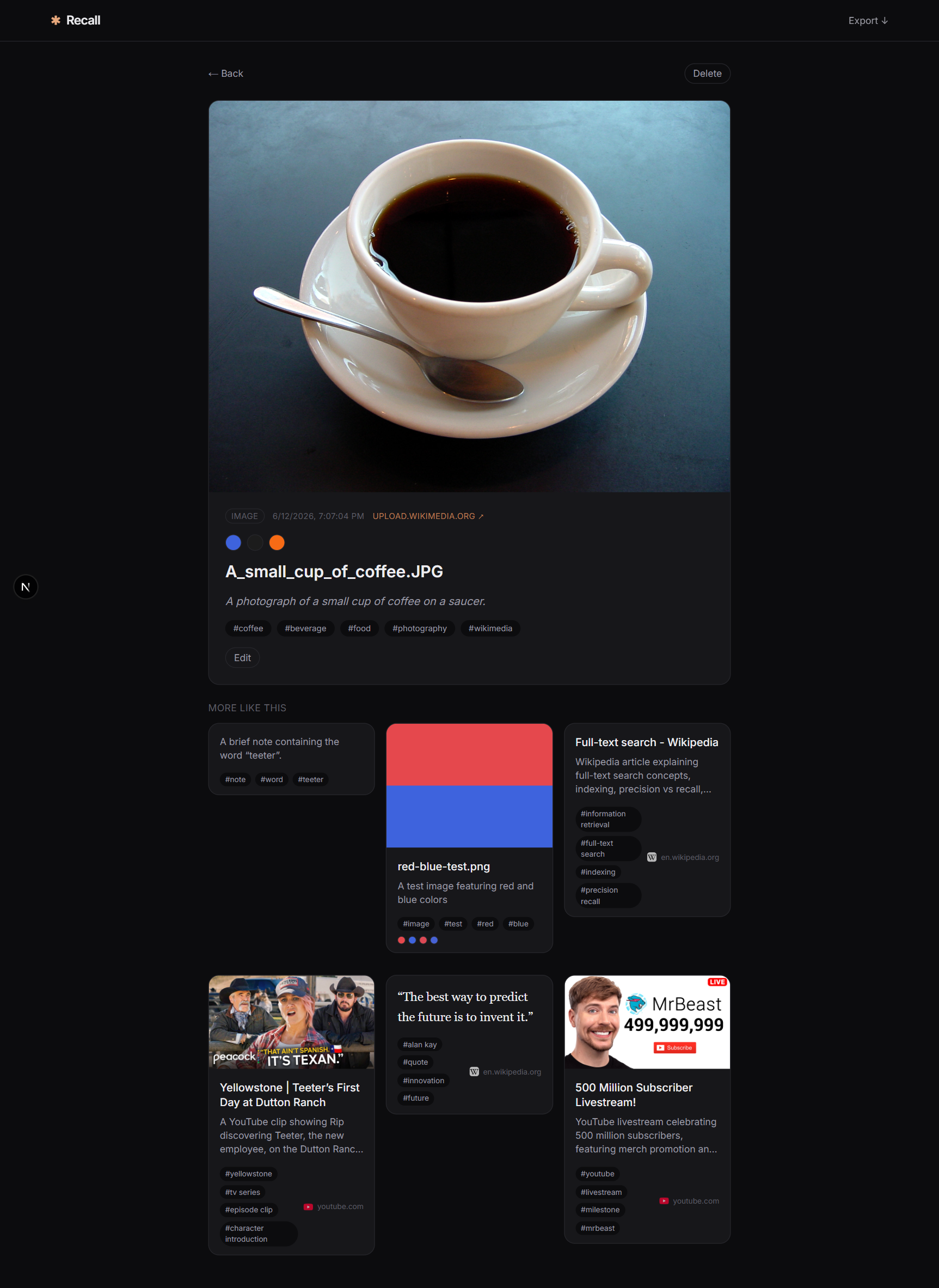
The whole thing is one Next.js app talking to Postgres (with pgvector) and MinIO for files — no sprawling microservices. There's a Plasmo browser extension for one-click saves and right-click capture of any link, image, or quote, and the visual card grid even lets you search images by their dominant color.
What I'm most proud of isn't any single feature — it's that the "smart" parts and the "private" parts aren't in tension. Local embeddings meant I never had to choose between semantic search and data ownership. That felt like the right way to build AI tooling: useful by default, yours entirely.
There's more I want to do — a mobile share sheet, email-forwarding ingestion, tag-rule "Smart Spaces" — but the core is real, tested, and self-hostable today. Recall is the tool I wanted to exist, so I built it.